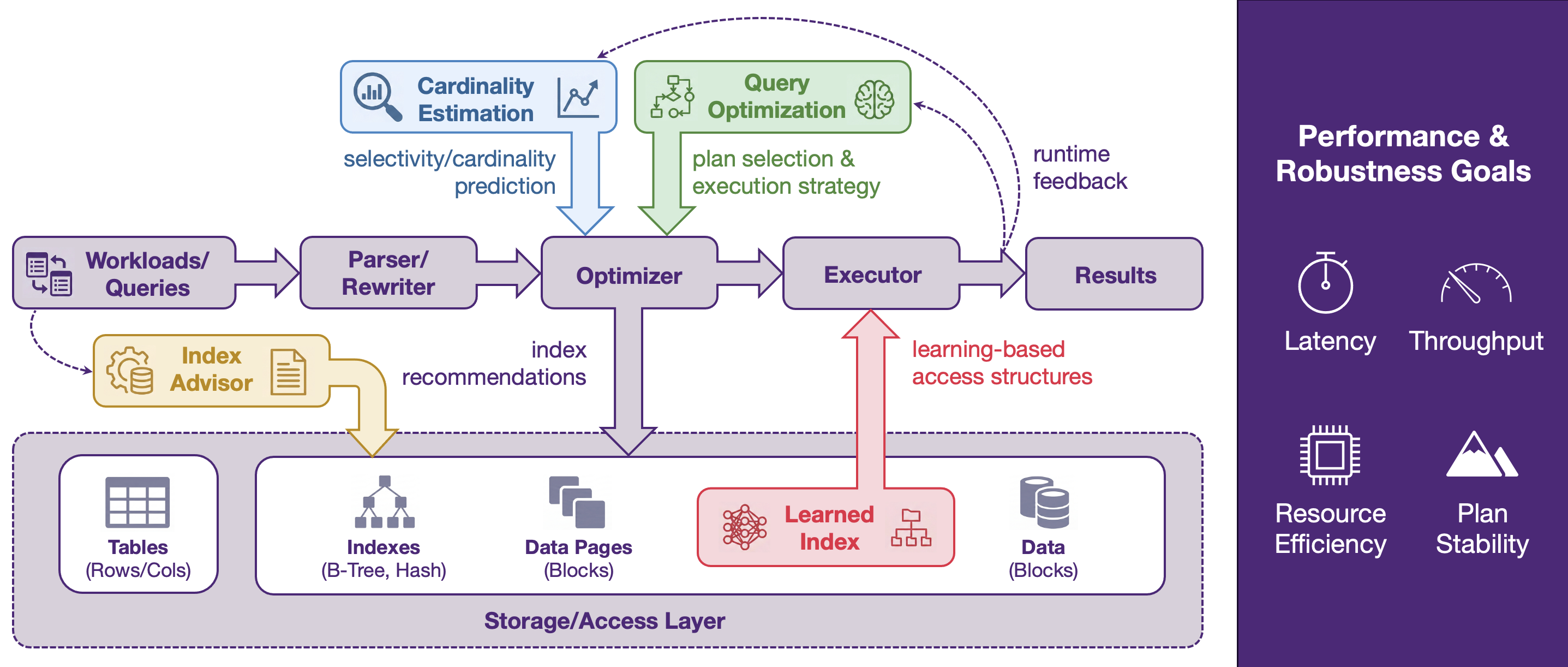
Autonomous AI Database System (AI4DB) explores how database systems can self-optimize with AI and machine learning, with a strong focus on practical, deployable solutions. Our projects in this theme span four key areas: learned index structures, cardinality estimation, index advising, and query optimization.
Across these topics, we study both new algorithms and system-oriented designs that work under realistic database constraints, such as storage behavior, workload dynamics, optimizer compatibility, and runtime efficiency. Our work includes cardinality estimation for emerging query types (e.g., string predicates and high-dimensional/vector similarity search), learning-based index recommendation under changing workloads, practical learned indexes for disk-resident settings, and learning-enhanced query optimization for real DBMS environments.
Together, these projects form a coherent research agenda on learning-enhanced database optimization, aiming to improve database performance end-to-end by strengthening the components that most directly affect plan quality and execution efficiency.
Topic 1: Learned Index
We study learned index structures as a new way to accelerate data access in database systems. Our work examines when learned indexes are effective in practice—especially in disk-resident settings—and develops designs that account for realistic factors such as storage behaviour, query patterns, and system overheads. We also investigate their trade-offs against traditional indexes through system-oriented evaluations and benchmarking.
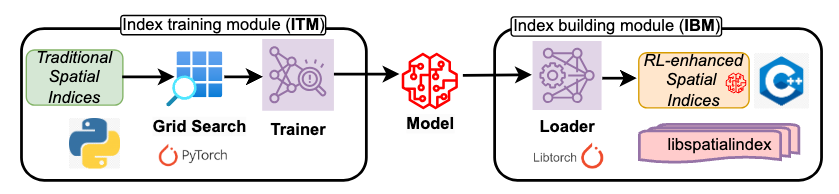
1.1) Benchmarking RL-Enhanced Spatial Indices Against Traditional, Advanced, and Learned Counterparts (ICDE’26) (Code)
This paper presents the first unified benchmarking framework for evaluating reinforcement learning–enhanced spatial indices (RLESIs) against traditional, advanced, and learned spatial indices in disk-based environments. It evaluates 12 representative indices across diverse datasets and workloads, including point, range, kNN, and spatial join queries. The results show that while RLESIs can achieve moderate improvements over traditional indices with careful tuning, they consistently underperform advanced and learned spatial indices and incur high training and tuning costs. These findings highlight important limitations of RLESIs and provide guidance for future research on practical learned spatial indexing.
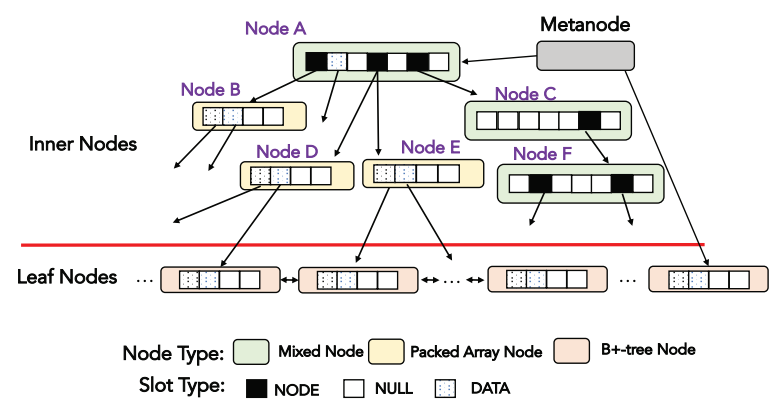
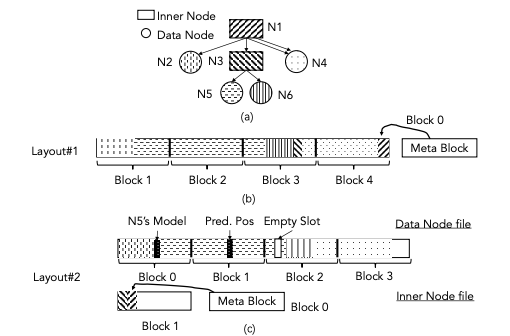
1.2) A Fully On-disk Updatable Learned Index (ICDE’24) (Code)
AULID proposes a fully on-disk updatable learned index designed specifically for disk-based database systems, where disk I/O dominates performance. It introduces a disk-efficient structure that reduces I/O cost by minimizing model traversal and optimizing node layouts for disk access. AULID supports efficient lookups, inserts, and updates while maintaining high accuracy and low storage overhead. Experiments show that AULID significantly improves lookup and update performance compared to traditional B+-trees and prior learned indexes in disk-resident settings.
1.3) Updatable Learned Indexes Meet Disk-Resident DBMS - From Evaluations to Design Choices (SIGMOD’23) (Code)
This paper studies whether updatable learned indexes are effective in disk-resident DBMS environments, where most real-world databases operate. It implements and evaluates several state-of-the-art learned indexes (e.g., PGM, LIPP, ALEX) and compares them against traditional B+-trees under various workloads. The results show that while learned indexes can outperform B+-trees in specific workloads, B+-trees remain highly competitive overall. Based on extensive analysis, the paper identifies key limitations of learned indexes on disk and proposes design principles to guide the development of efficient on-disk learned indexes.
Topic 2: Cardinality Estimation
We work on cardinality estimation for modern query types that are difficult for traditional estimators, including string predicates and high-dimensional/vector similarity search. Our goal is to build estimators that are not only accurate, but also robust, lightweight, and practical for integration with real query optimizers. This line of work targets one of the most important bottlenecks in cost-based query optimization.
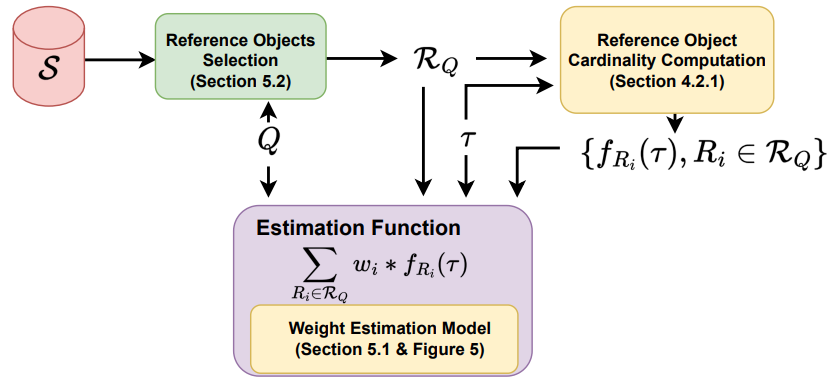
2.1) Cardinality Estimation for Similarity Search on High-Dimensional Data Objects: The Impact of Reference Objects (VLDB’25) (Code)
This paper studies cardinality estimation for similarity search on high-dimensional data (CE4HD), which is essential for query optimization in vector databases and embedding-based applications. It proposes a novel reference-object–based approach, where selected data objects with similar cardinality patterns are used to estimate the query cardinality efficiently and accurately. The paper introduces two methods—SRCE (single-reference) and MRCE (multi-reference)—that leverage reference objects and lightweight models to improve robustness and efficiency. Experiments show that the proposed methods achieve up to 10× faster estimation and up to 136× lower Q-error compared to prior approaches such as SimCard and SelNet.
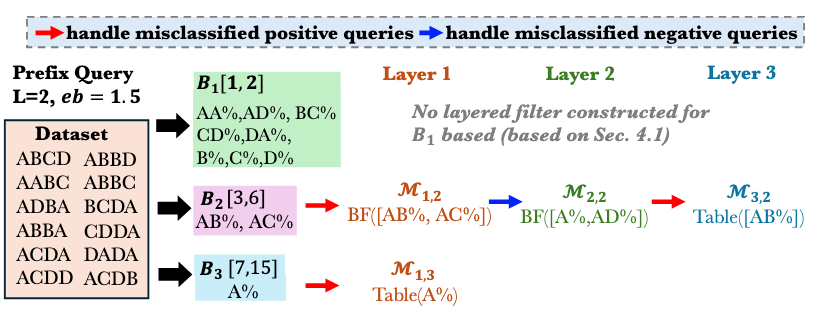
2.2) LEARNT: A Practical Estimator for Cardinality of LIKE Queries with Formal Accuracy Guarantees (under review) (Code)
This paper proposes LEARNT, a practical and theoretically grounded estimator for cardinality estimation of LIKE queries on string data, including prefix, suffix, and substring patterns. It reformulates estimation as a bucket classification problem, enabling formal Q-error bounds when queries are correctly classified. LEARNT introduces a memory-efficient bucketed layered filter architecture using Bloom filters and lookup tables, along with dedicated strategies for handling empty-answer queries and long patterns. Experiments on real datasets show that LEARNT achieves 1.3–1.7× lower estimation error and up to 70× faster construction compared to state-of-the-art methods, while maintaining low storage overhead.
Topic 3: Index Advisor
We develop learning-based index advisors that recommend effective index configurations under both static and evolving workloads. Our projects explore techniques such as reinforcement learning and transfer learning to improve recommendation quality while reducing tuning cost. The focus is on practical physical design support that can adapt to real workload changes and system constraints.
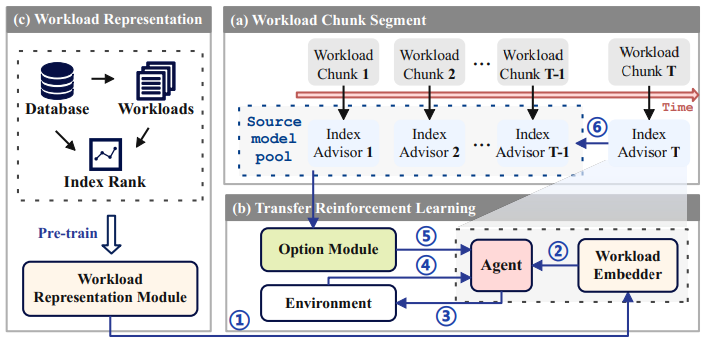
3.1) Leveraging Dynamic and Heterogeneous Workload Knowledge to Boost the Performance of Index Advisors (VLDB’24) (Code)
This paper proposes BALANCE, a learning-based index advisor designed for dynamic and heterogeneous workloads where query patterns evolve over time. BALANCE builds lightweight index advisors on sequential workload chunks, transfers learned policies from historical workloads to reduce retraining cost, and uses contrastive learning to generate effective workload representations. This enables accurate and efficient index recommendations while adapting to workload shifts. Experiments show that BALANCE improves index performance by about 10% over prior methods (e.g., SWIRL) while reducing training overhead by 35% on average.
3.2) An Index Advisor Using Deep Reinforcement Learning (CIKM’22) (Code)
This paper studies the index selection problem, which aims to choose the best set of indexes to minimize workload execution cost under storage or number constraints, a known NP-hard problem. It proposes a deep reinforcement learning–based index advisor that integrates heuristic candidate generation with a Deep Q Network (DQN) to recommend both single-attribute and multi-attribute indexes while modeling their interactions. The approach enables more effective exploration of index combinations and supports multiple-index access to tables. Experiments show that the proposed method achieves better workload performance than traditional greedy and optimization-based index advisors.

Topic 4: Query Optimization
We study learning-enhanced query optimization to improve plan selection in real DBMS environments, including parameterized and concurrent workloads. Our work focuses on practical approaches—such as learned ranking and plan reuse—that can augment existing optimizers without requiring major changes to DBMS internals. We also investigate broader optimizer design challenges and foundations through empirical studies and system-level analysis.
4.1) Practical Parameterized Query Optimization via Efficient Plan Reuse and List-wise Ranking (SIGMOD’26) (Code)
PLARQ is a practical learned optimizer designed for parameterized query optimization (PQO), where the same query template is repeatedly executed with different parameter values. It introduces a plan reuse strategy that retrieves high-quality candidate plans from a precomputed pool based on query similarity, and a list-wise attention-based ranking model to select the best plan efficiently. PLARQ integrates seamlessly with PostgreSQL without modifying optimizer internals and achieves significant performance improvements, with up to 420× speedup over PostgreSQL and up to 2× over existing learned methods.
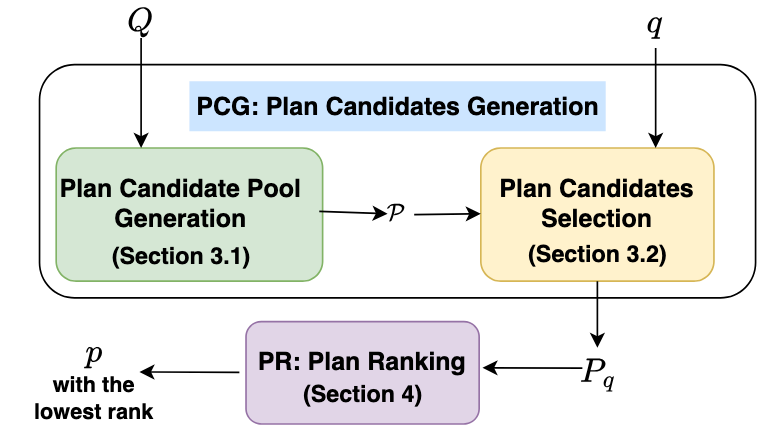
4.2) RankPQO: Learning-to-Rank for Parametric Query Optimization (VLDB’25) (Code)
RankPQO is a learning-to-rank framework for parametric query optimization that generates diverse candidate plans and selects the best one based on parameter values. Instead of predicting absolute cost, it ranks plans using relative performance, improving robustness and accuracy. It achieves up to 2.57× speedup over PostgreSQL and outperforms prior PQO methods.
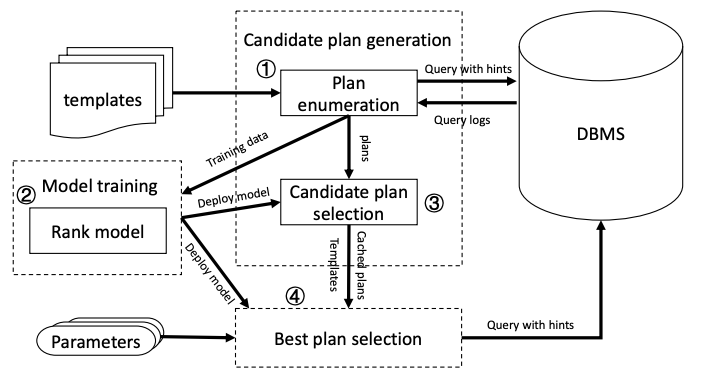
4.3) Lemo: A cache-enhanced learned optimizer for concurrent queries (SIGMOD’24)
Lemo is a learned query optimizer designed for concurrent query execution, where multiple queries run simultaneously and may share common subqueries. It uses a Transformer-based value network to predict query latency and guide plan generation, and a shared buffer manager to cache and reuse intermediate results, reducing redundant computation. By jointly optimizing plan selection and subquery reuse under concurrency, Lemo significantly improves query performance compared to traditional optimizers.
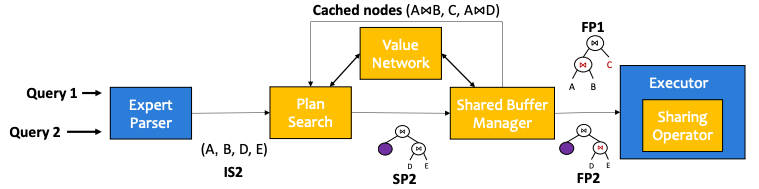
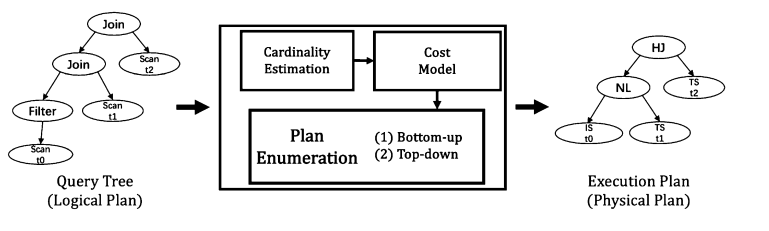
4.4) A Survey on Advancing the DBMS Query Optimizer: Cardinality Estimation, Cost Model, and Plan Enumeration (Data Science and Engineering’21)
This paper surveys techniques for improving cost-based database query optimizers, focusing on three core components: cardinality estimation, cost models, and plan enumeration. It explains that inaccuracies in cardinality estimation are the main cause of suboptimal query plans, and reviews traditional methods (e.g., histograms and sampling) as well as modern learning-based approaches. The paper also highlights key limitations of existing optimizers and outlines future directions, especially integrating machine learning to build more accurate and robust optimization frameworks.